Hace unas semanas Sergio me propuso hacer una guía de Screaming Frog. Yo acepté encantado. El problema con este tipo de guías es no hacer un refrito de lo que ya han escrito 20.000 personas anteriormente. Al final la herramienta tiene las opciones que tiene por lo que la mayoría de este tipo de contenidos es muy similar.
Por este motivo he querido hacer algo diferente para aportar algo de valor.
Una parte inicial pensada para aquellos que no la han usado o tienen poca experiencia con su manejo, y una segunda parte a modo de casos prácticos para aquellos SEO’s que acumulan ya algo de experiencia.
¡Empezamos!
¿Qué me voy a encontrar en este artículo?
- 1 Screaming Frog para principiantes
- 2 Configuración inicial
- 3 Modo
- 4 Analizando la información rastreada
- 5 Exportar información (reportes)
- 6 API’s
- 7 Alternativas
- 8 Ejemplos de uso de Screaming Frog más avanzados
- 8.1 ¿Cómo rastrear un directorio concreto?
- 8.2 ¿Cómo rastrear un subdominio concreto?
- 8.3 ¿Cómo detectar broken links internos en tu web?
- 8.4 ¿Cómo detectar imágenes con el atributo ALT vacío?
- 8.5 ¿Cómo mejorar mi enlazado interno I?
- 8.6 ¿Cómo mejorar mi enlazado interno II?
- 8.7 ¿Cómo configurar el archivo robots.txt correctamente?
- 8.8 Cómo detectar páginas lentas o con errores de WPO
- 8.9 ¿Cómo detectar errores tras una migración?
- 8.10 ¿Cómo detectar problemas en páginas que no rankean bien?
- 8.11 ¿Cómo hacer un análisis del contenido que mejor funciona en tu blog?
- 8.12 ¿Cómo identificar errores de renderizado?
Screaming Frog para principiantes
Qué es Screaming Frog
Screaming Frog SEO Spider es un software de rastreo de sitios web. Un crawler que te permite rastrear las URL de cualquier web y obtener elementos clave para analizar y auditar el site a nivel SEO. Podríamos decir que es sin duda una parte muy importante a la hora de realizar una auditoría SEO.
Seguramente sea la mejor, o una de las tres mejores herramientas, que no le puede faltar a ningún SEO.
Esta herramienta está desarrollada por una agencia inglesa, Screaming Frog, la cual ha desarrollado otro genial producto que es un analizador de logs.
Cuánto cuesta
Puedes probarla gratis pero con ciertas limitaciones. No podrás rastrear más de 500 url’s y algunas de las opciones están capadas.
La versión de pago, aunque ha subido en los últimos años, tiene un precio de 150€ al año. Una inversión buenísima para todo lo que ofrece.
Descarga e instalación
Screaming Frog es una herramienta que te descargas en tu PC, no es un crawler online. Su instalación no tiene ningún misterio, puede descargarla desde su propia página.
Si te decides a comprarla, una vez la hayas descargado e instalado en tu ordenador, deberás introducir tu licencia para poder hacer un uso completo de la “rana”.
Partes de la herramienta
Screaming Frog se compone de un menú navegacional que se mantiene siempre. Y tres paneles en el modo Spider (el más usado). Una parte central con información de lo que se va encontrando durante el rastreo. Un sidebar a la derecha donde podemos ver un resumen de las principales métricas o configurar las API’s, por ejemplo. Y un panel inferior donde podemos ir más al detalle con información de cada url que seleccionemos.
Configuración inicial
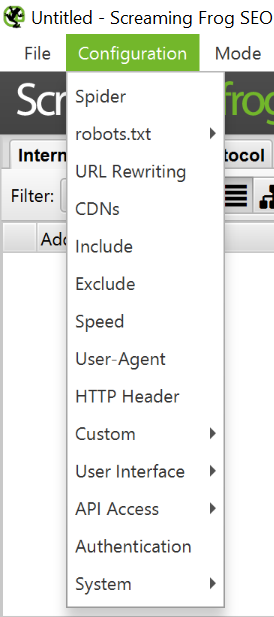
Spider
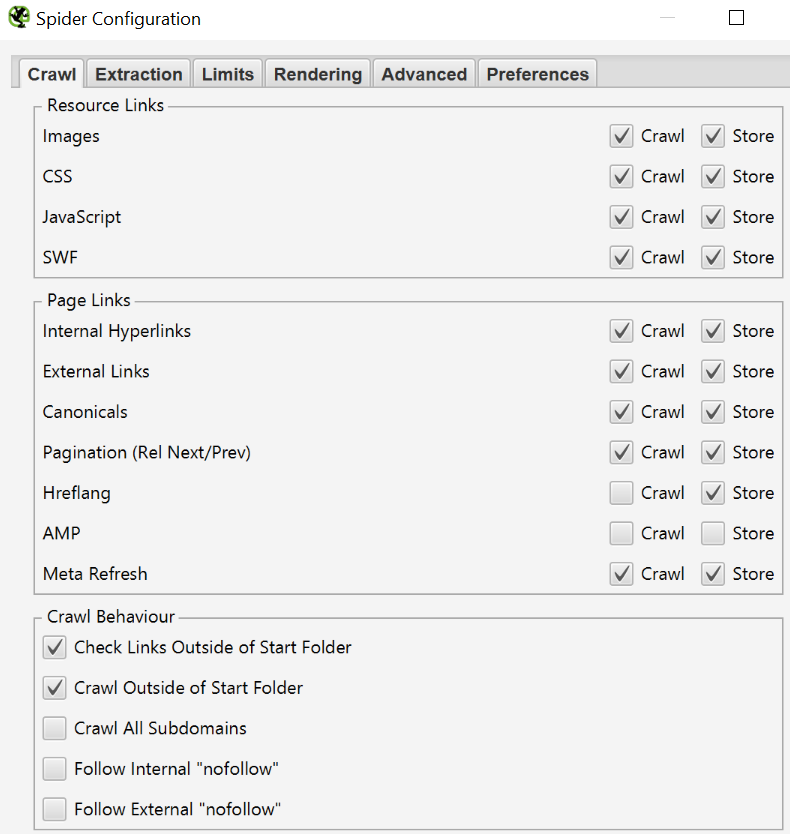
Esta configuración es una de las más importantes, especialmente cuando queremos crawlear grandes sites. Se compone de 6 pestañas:
- Crawl: Seleccionamos los elementos que queremos que el bot rastree y/o almacene. Podemos decirle que siga los archivos .css, que rastree los canonicals, las paginaciones, los subdominios, los nofollow… por citar algunos ejemplos.

- Extracción: Aquí podemos configurar qué elementos queremos que se extraigan para visualizarlos en el panel y analizarlos. Algunos ejemplos: titles, h1, directivas del meta robots, datos estructurados, Html renderizado… etc.
- Límitaciones: Pestaña importante cuando no queremos rastrear todo el site. Podemos limitar la profundidad de carpetas (Crawl Depth), el nº de cadenas de redirecciones que se rastrean, nº máximo de links que sigue el bot por url…
- Renderizado: Podemos seleccionar si queremos que el bot renderice Javascript o se limite sólo a Html.
- Avanzado: en esta pestaña tenemos diversas opciones. Una de ellas es si queremos pausar la herramienta si consume mucha memoria. En el rastreo de grandes sites es bastante habitual que tengamos que incrementar la memoria (puedes obtener más información en este link). Además podemos configurar si se siguen o no siempre las redirecciones, si se reportan o no las url’s canonizadas, el tiempo que el bot espera una respuesta del servidor…etc
- Preferencias: aquí podemos editar los caracteres o píxeles que son reportados. Útil para analizar si nuestros titles se ven o no completamente en las SERPS, por ejemplo.
Robots.txt
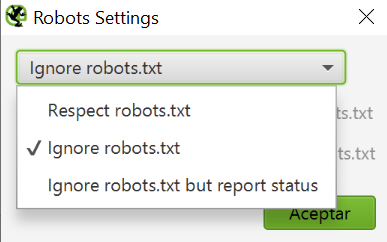
En este apartado podemos hacer testeos antes de editar nuestro robots.txt. Fundamental si quieres saber las implicaciones que tendrá un cambio en este archivo.
Por un lado tenemos la opción de decirle al bot que respete o no las directivas del robot.txt.
Por otro podemos subir el robots (o los robots de los diferentes subdominios), editarlos, y lanzar el rastreo para ver cuál es el comportamiento.
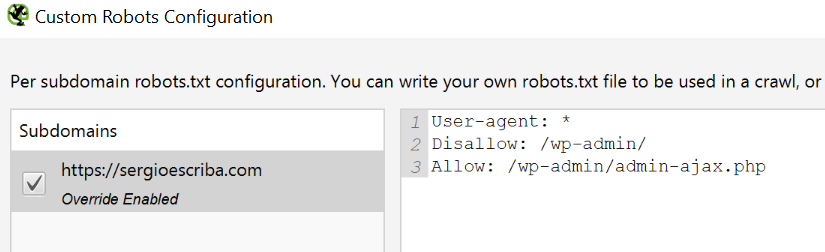
URL Rewriting
Configuración que puede ser útil para hacer reemplazos masivamente en url’s. Algo que podríamos hacer también en excel tras exportar el crawl, pero de esta forma ahorramos tiempo.
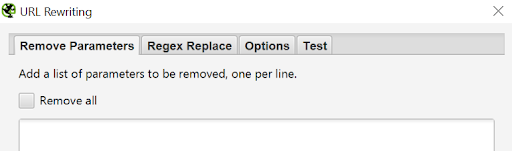
Una de las opciones es Regex Replace o expresiones regulares. Opción muy potente ya que te permite hacer muchos cambios con un par de líneas de código. En este post puedes aprender más sobre expresiones regulares.
CDN’s
Si la web que queremos rastrear utiliza CDN’s, podemos incluirlos para que sean tratados como url’s internas y poder analizarlas junto con el resto de páginas del site.
Include y exclude
Configuración para incluir o excluir url’s, directorios o subdominios enteros. Otra forma de optimizar el rastreo y conseguir que sólo se crawlee lo que nos interesa.
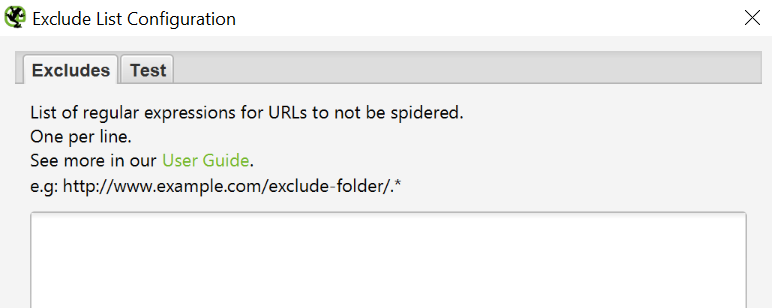
Velocidad
Podemos editar la velocidad en nº de url’s por segundo que la herramienta va a rastrear. A más url’s por segundo más recursos consumirá Screaming Frog por lo que a nivel memoria puede ser un problema.
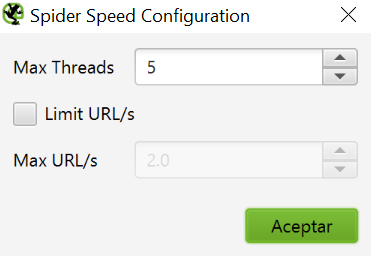
User – Agent
Uno de los fuertes de “la rana”. Podemos simular el comportamiento de rastreo que tendría Googlebot, Bingbot, Chrome, Safari… y así detectar posibles problemas. Especialmente útil en entornos de desarrollo, cuando no disponemos de información de otras herramientas como Google Search Console y necesitamos anticipar problemas futuros.
HTTP Header & Authentication
Algunos sites muestran un contenido u otro en función del lenguaje detectado o de las cookies, por ejemplo. En este apartado podemos lanzar rastreos para analizar el comportamiento haciendo variaciones en los HTTP Headers.
Puedes profundizar más en la documentación de Mozilla y en este post.
Búsquedas personalizadas y extracción de datos específicos
Búsquedas personalizadas
No permite buscar en el código fragmentos específicos. Por ejemplo, podríamos intentar detectar qué páginas no tienen el código de Analytics implementado.
Extracción de datos
Screaming Frog por defecto extrae y muestra algunos de los elementos HTML más importantes como titles, description, encabezados… etc. En este apartado podemos añadir nosotros qué elementos queremos extraer.
Por ejemplo, vamos a extraer todos los autores del blog de Sergio para saber quiénes han escrito. Nos vamos a un artículo > clic derecho > inspeccionar elemento sobre el nombre del autor.
Ahora hacemos clic sobre el nombre en el código fuente > copy > full XPath
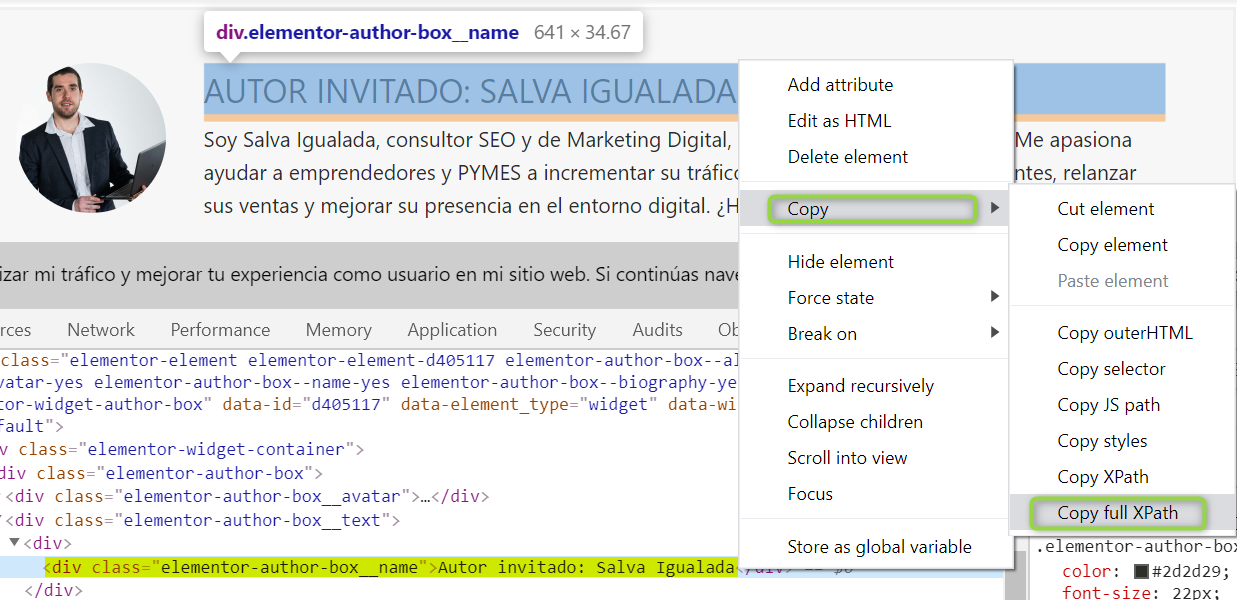
Y pegamos en Screaming Frog.

Como resultado:

Modo
Spider
El modo araña es el que vemos por defecto. Introducimos una url y la herramienta va siguiendo los enlaces que encuentra a su paso y almacenando todo tipo de información.
List
En esta opción nosotros subimos un montón de url’s y SF rastrea sólo dichas url’s. Puede ser útil cuando sólo queremos analizar un grupo reducido de páginas o url’s que no son accesibles mediante la navegación como páginas antiguas, landing exclusivas de ppc, el archivo sitemap… etc.
SERP
Parecido a la opción lista. En este caso scrapea los resultados de búsqueda dándonos información del title y la indexabilidad de la página.
Analizando la información rastreada
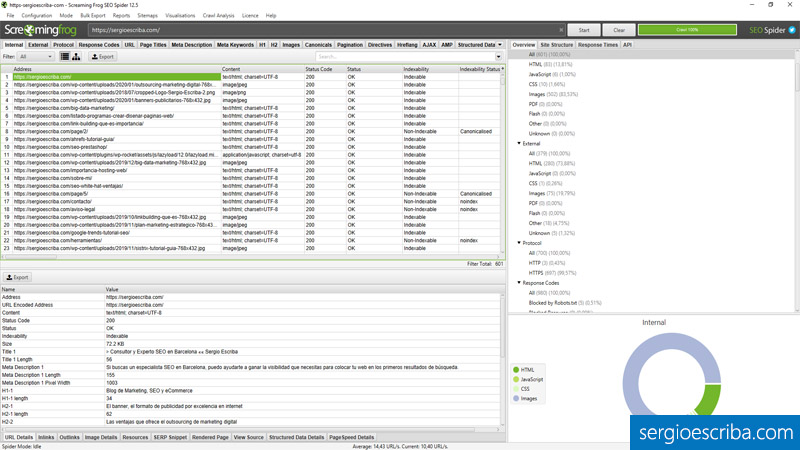
Internal: Analizando las URLs del proyecto
En esta pestaña veremos información relativa a la web rastreada. Dependiendo de cómo la hayamos configurado podremos analizar también los subdominios o los CDN del site.
External: Analizando los enlaces salientes externos
Información de todos los enlaces salientes que apuntan a otras webs.
Protocol: Revisando si tenemos URLs con http y https
Información tanto interna como externa de url’s con HTTP y HTTPS. Útil para solucionar problemas de contenido mixto.
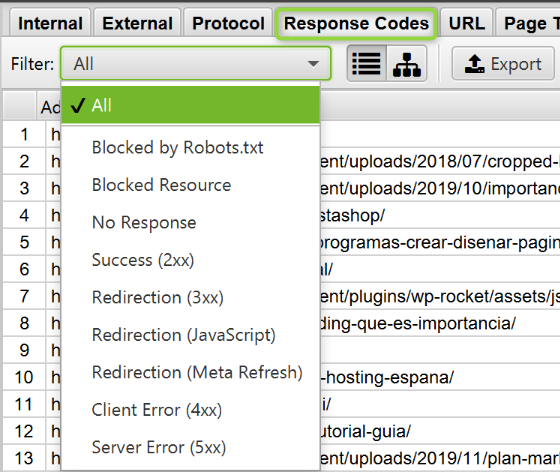
Analizando códigos de respuesta
Cada vez que se solicita una url el servidor emite una respuesta. Esta es la información que podemos obtener:
- Bloqueado por robots.txt: url’s bloquedas por nuestro archivo robots.
- No hay respuesta: cuando el servidor tarda mucho en dar una respuesta.
- 2XX: url’s que cargan correctamente.
- 3XX: redirecciones desde el server.
- Redirección (Javascript): redirecciones ejecutadas con Javascript.
- Redirección (Meta Refresh): redirecciones mediante meta refresh.
- 4XX: páginas no encontradas.
- 5XX: errores del servidor.
Si quieres conocer más sobre las posibles respuestas del servidor échale un ojo a esta información de Wikipedia.
Resto de pestañas
Información de URLs, titles y descriptions, encabezados, imágenes, directives, hreflang, AMP, información de API’s…
Exportar información (reportes)
Exportación de una pestaña concreta
Podemos exportar a excel la información de cualquiera de las pestañas del panel principal.
Exportación de información concreta
Si lo que queremos es descargar información concreta lo idóneo es hacerlo desde el menú:
- Bulk export
- Informe de links internos.
- Informe de links externos.
- Informe de todos los anchor text.
- Informe de imágenes.
- Informe de códigos de respuesta.
- Informe de canonicals.
- Informe de datos estructurados.
- …etc
- Reports
- Crawl overview. Un resumen con los principales indicadores. Mismos datos que los que encontramos en el panel de la derecha.
- Informe de redirecciones (todas y bucles de redirecciones).
- Informe de canonicals (cadenas y no indexables).
- Informe de paginación.
- Informe de Hreflang.
- Informe de contenido mixto o inseguro.
- …etc
API’s
Y llegamos a uno de los fuertes de Screaming Frog. Su conexión con ciertas API’s que hace que el valor de los datos extraídos aumente exponencialmente. Algunas de las conexiones son gratuitas (Google Analytics, Search Console, PageSpeed) y otras de pago (Majestic, Ahref y Moz). Vamos a ver las API’s que son gratuitas y que son accesibles a todo el mundo.
Google Analytics
Conectarse a la API no tiene ningún misterio. Vinculamos SF a la cuenta gmail donde tenemos las propiedades de GA y listo. Podemos elegir la vista que nos interesa, el segmento, el rango de fechas, métricas, dimensiones y opciones generales.
Google Search Console
Mismo proceso para conectarnos a la API de Search Console. Podemos seleccionar propiedad, rango de fechas, filtros (pais, dispositivo…) y opciones generales.
PageSpeed Insights
La conexión de PageSpeed no es tan intuitiva (al menos para mí). Siguiendo las indicaciones del link de Screaming Frog no está claro, en mi caso he conseguido una API key siguiendo las indicaciones de Google en esta página.
Una vez te has conectado a la API, los datos que ofrece son una maravilla. No se limita a cifras de rendimiento sino que también te indica los milisegundos que puedes ahorrarte si aplicas ciertas mejoras.
Alternativas
En mi opinión, relación calidad precio, para sites pequeños y grandes Screaming Frog es la mejor herramienta. Quizá se quede corto a nivel de potencia si quieres rastrear un site gigante con millones de url’s.
Si por lo que sea SF no te acaba de convencer, aquí te dejo algunas de las herramientas de rastreo más famosas del mercado:
Deepcrawl
- Desde 12 euros al mes.
- Es una herramienta online.
- Tiene free trial.
Sitebulb
- Desde 10 libras al mes.
- Requiere instalar la herramienta en tu pc.
- Tiene free trial.
Xenu
- Herramienta gratuita.
- Requiere instalar la herramienta en tu pc (no te asustes con la interfaz de su web, no es un virus!).
Botify
- No anuncian el precio.
- Es una herramienta online.
- Puedes solicitar una demo.
Oncrawl
- Desde 49 euros al mes.
- Es una herramienta online.
- Tiene free trial.
Ejemplos de uso de Screaming Frog más avanzados
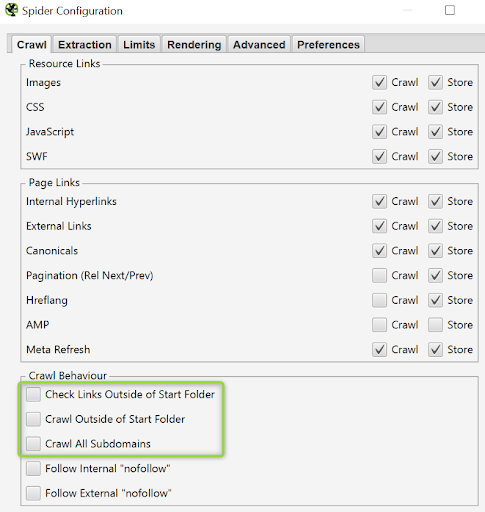
¿Cómo rastrear un directorio concreto?
Puede darse el caso de que necesitemos rastrear sólo lo que cuelga de un directorio en particular. Para ello, desde la opción del menú Configuración, dejaremos sin marcar las opciones de:
- Chequear links fuera del directorio.
- Rastrear fuera del directorio desde donde empezamos a rastrear.
- Rastrear subdominios (por si acaso).
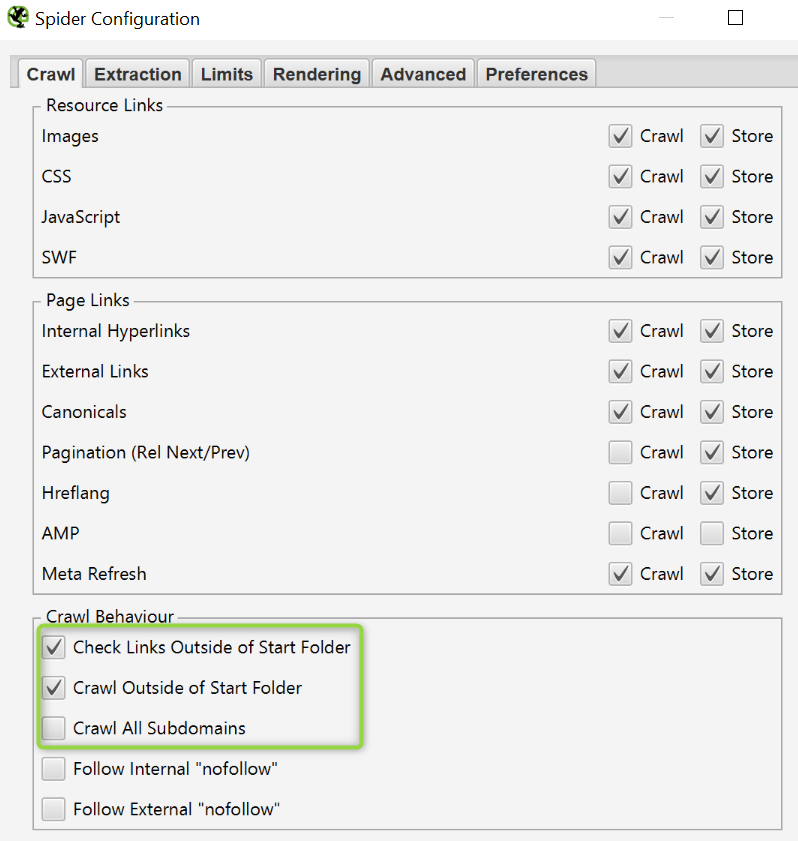
¿Cómo rastrear un subdominio concreto?
Parecido al caso anterior, pero ahora sí marcaremos las siguientes opciones para que rastree todo el subdominio:
- Chequear links fuera del directorio.
- Rastrear fuera del directorio desde donde empezamos a rastrear.
Dejando sin marcar la opción de rastrear todos los subdominios.
¿Cómo detectar broken links internos en tu web?
Los enlaces rotos son aquellos que apuntan a páginas inexistentes, los que la respuesta del server es un 4XX. Hay que tener en cuenta que nos podemos encontrar dos casuísticas:
Enlaces rotos directos
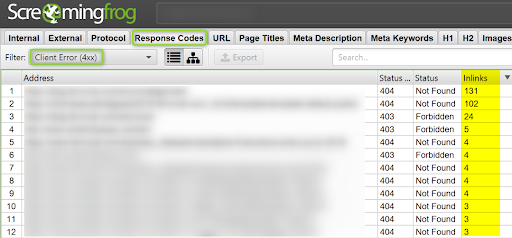
Son aquellos que apuntan directamente a un 404. Son fácilmente identificables. Si encuentras muchos en tu site tendrás que priorizar e ir solucionándolos poco a poco. Una forma es filtrar por Inlinks para dejar de enlazar aquellas páginas que tienen más enlaces rotos apuntando así mismas.
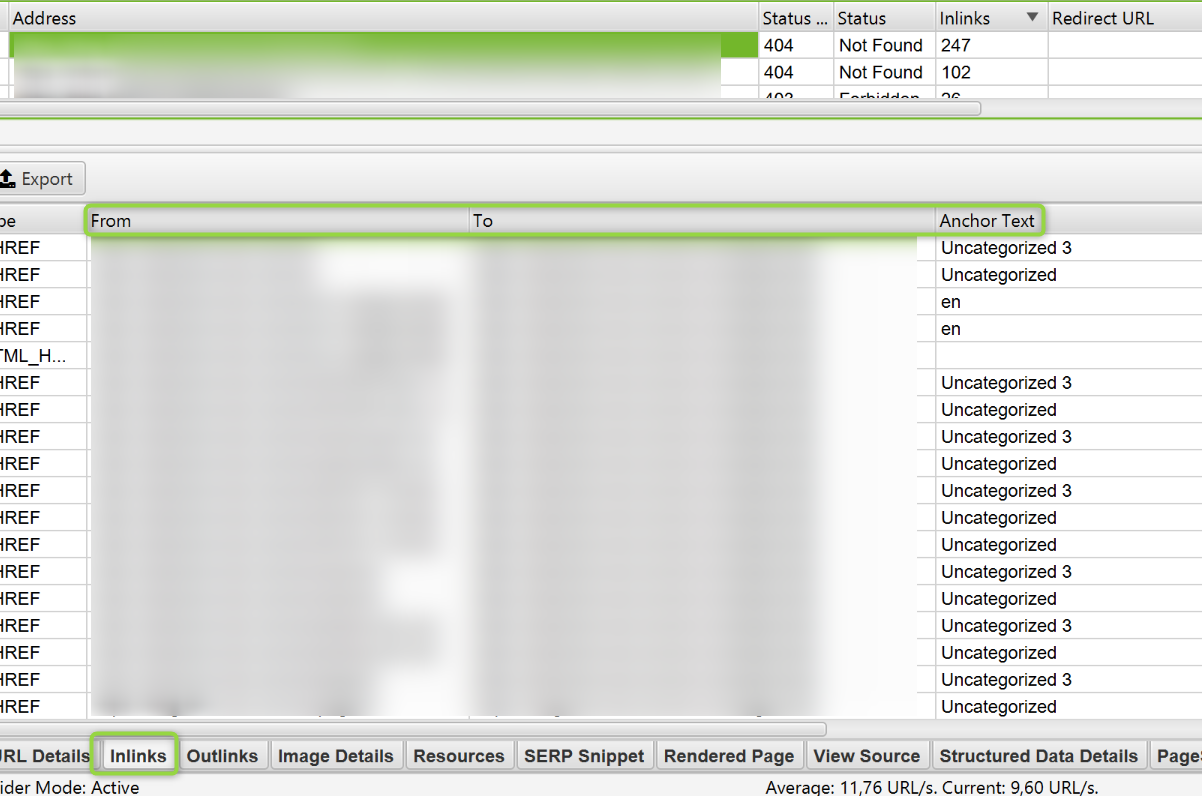
Una vez que hayas hecho esto, selecciona una url, en el panel inferior selecciona la pestaña Inlinks. La información que ahí puedes observar es desde qué páginas se está enlazando a ese 404.
A veces, aunque una página 404 tenga muchos enlaces apuntando así misma, puede solucionarse en dos minutos. Esto ocurre en enlaces desde partes comunes de la web como el menú, el footer o el sidebar. Son este tipo de 404 los que más impacto negativo tienen y deberemos solucionar primero.
Enlaces rotos tras varias redirecciones
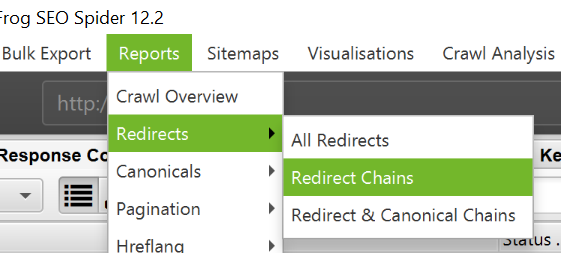
Estos broken links son más puñeteros ya que a simple vista son redirecciones. Lo que ocurre es que tras una redirección, dos, tres… (he llegado a ver hasta 12) al final se llega a un not found.
Para descubrir este tipo de broken links tendremos que descargarnos el reporte Redirecciones en cadena.
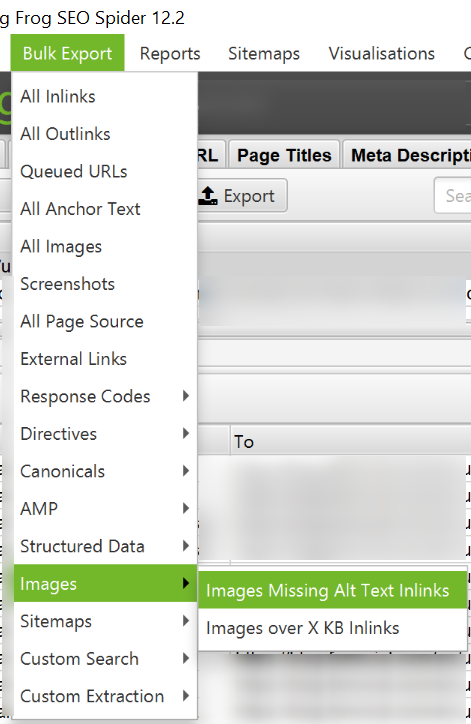
¿Cómo detectar imágenes con el atributo ALT vacío?
Podemos conseguir un informe con todas las imágenes sin ALT y en qué páginas se encuentran cargadas para poder solucionarlo desde Bulk export.
¿Cómo mejorar mi enlazado interno I?
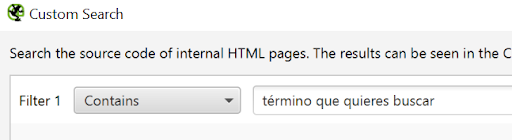
Una forma de encontrar oportunidades de enlazado interno es mediante la opción de Configuración > Custom > Search
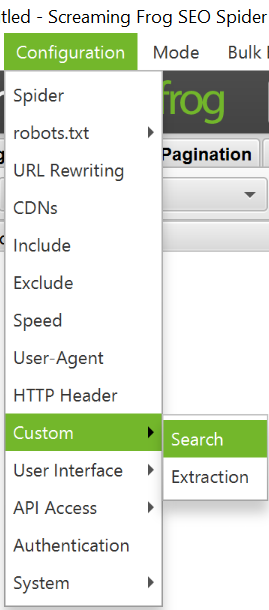
Añadimos los términos que queremos trabajar a nivel link sculping.
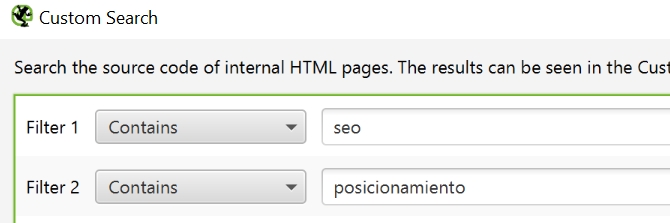
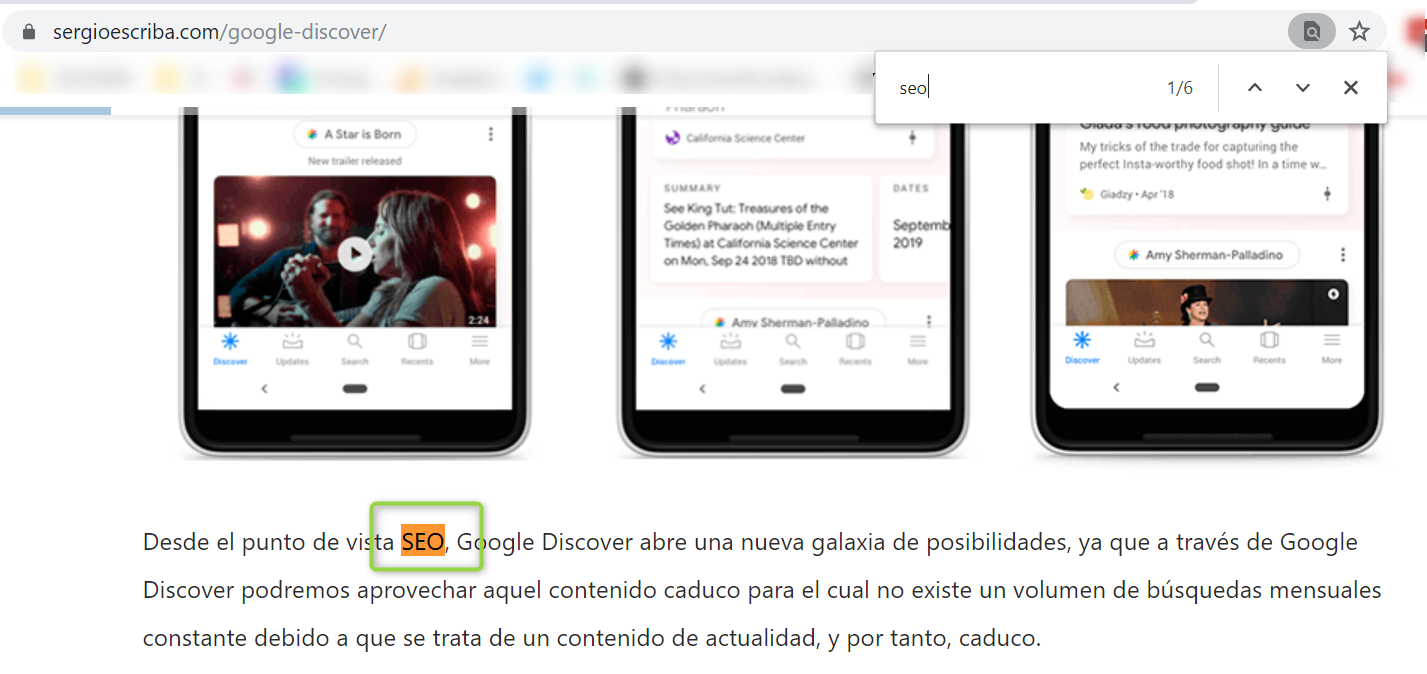
En la pestaña Custom Search vamos a ver el número de veces que se repiten la palabra SEO y Posicionamiento. De esta forma, si queremos trabajar el posicionamiento de algún artículo concreto sobre esta temática podemos añadir links con estos anchor text.
Vemos que en el post de Google Discover se utiliza el término SEO 13 veces (en el código fuente).
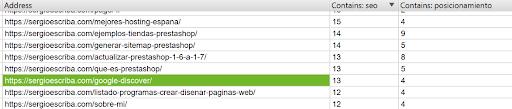
Vemos como dentro del contenido se utiliza la palabra SEO y no enlaza a ningún sitio, una oportunidad de linkar a una página que queramos potenciar por dicho término.
¿Cómo mejorar mi enlazado interno II?
Otra opción es descargarnos el informe de All Inlinks. Creamos una tabla dinámica y de un vistazo podemos ver los anchor text más utilizados en el blog de Sergio.
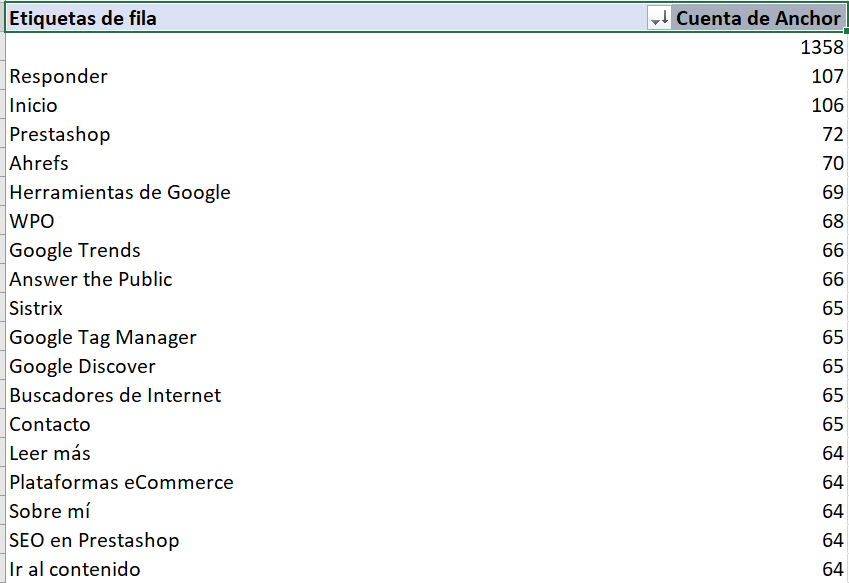
De esta forma podemos ver rápidamente si los términos más enlazados corresponden con nuestra estrategia de posicionamiento. En breve actualizaré mi post de excel para seo con información para dominar tablas dinámicas, por si quieres dominar excel.
¿Cómo configurar el archivo robots.txt correctamente?
Podemos hacer testeos de nuestro robots.txt y de esta forma asegurarnos de que todo funciona correctamente.
Imaginemos que queremos evitar que ciertas herramientas de análisis rastreen nuestro site. A modo de ejemplo vamos a configurar el robots para que Screaming Frog sea incapaz de rastrear nuestro site.
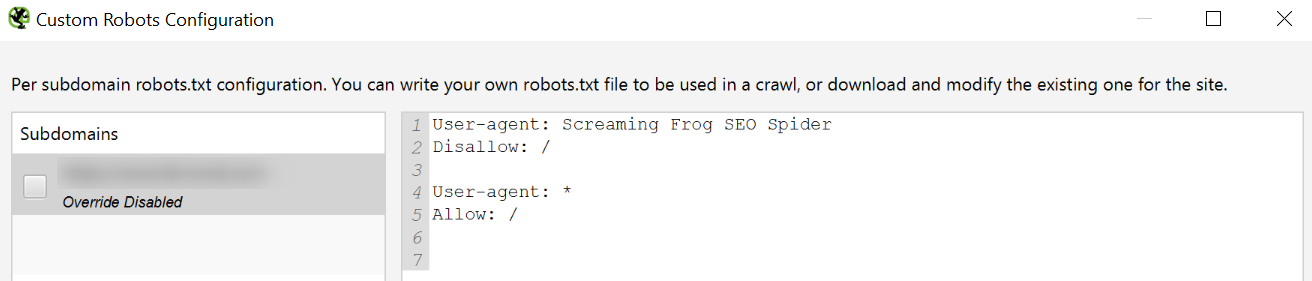
Evidentemente, en el caso de Screaming Frog es absurdo ya que existe la configuración Ignore robots.txt, pero quizá queramos configurarlo para ciertos bots que scrapean y copian nuestro contenido automáticamente.
Cómo detectar páginas lentas o con errores de WPO
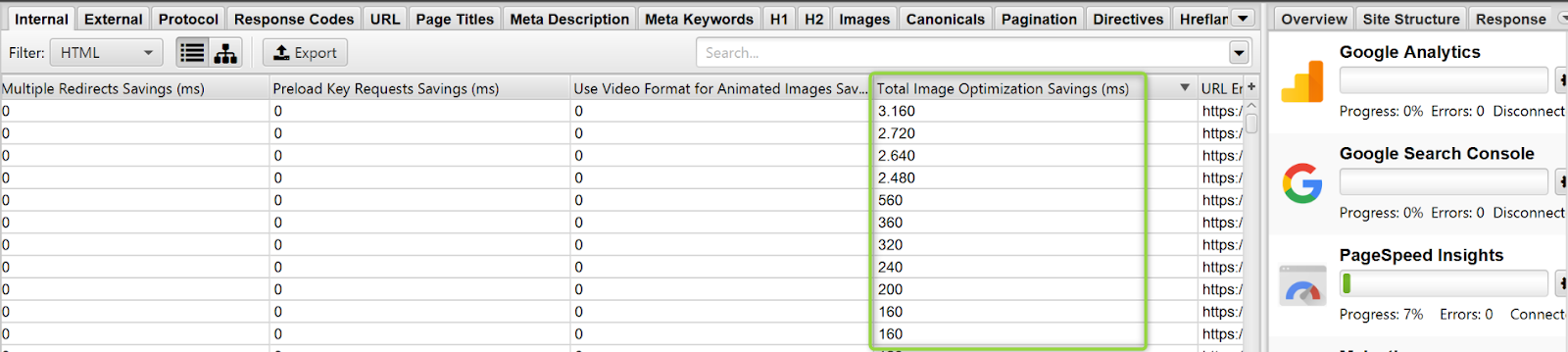
Con la conexión a la API de PageSpeed (visto en el apartado de API’s) podemos tener información y estimaciones de mejora, algo muy valioso y útil para priorizar acciones.
Por ejemplo, en el siguiente proyecto podemos mejorar más de 3 y 2 segundos si optimizamos las imágenes cargadas en algunas páginas.
¿Cómo detectar errores tras una migración?
Uno de los problemas SEO que puede arruinar nuestro proyecto es no configurar bien las redirecciones. Esto se complica especialmente en grandes sites. Un análisis que podemos realizar para identificar errores tras una migración es conectar la API de Analytics y coger un periódo de tiempo que abarque un mes antes y un mes después de la migración.
Es importante marcar la opción para que rastree url’s descubiertas en Analytics.
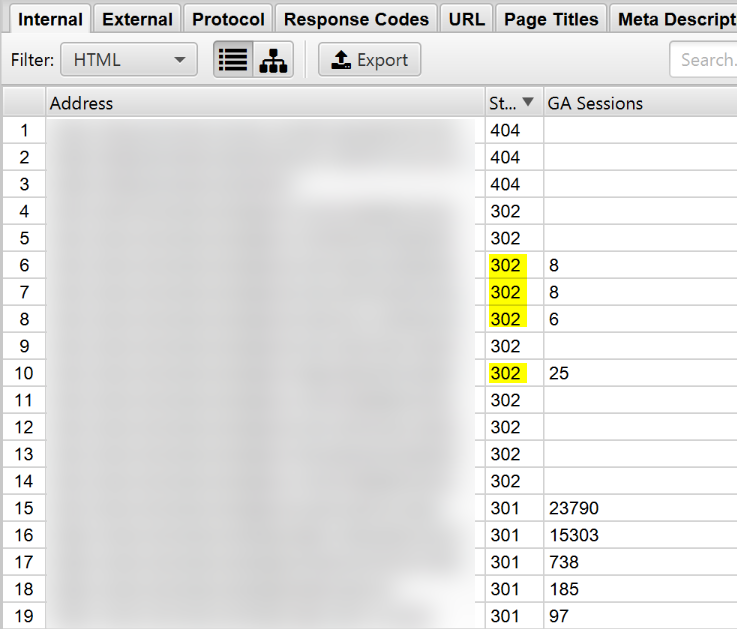
En el siguiente ejemplo vemos como antiguas url’s que estaban captando tráfico orgánico no se han redirigido bien ya que la redirección es temporal no un 301.
¿Cómo detectar problemas en páginas que no rankean bien?
A veces tenemos páginas que no rankean bien o, si están bien posicionadas pero aún podrían estarlo mejor. Mediante el enlazado interno podemos potenciar más o menos unas páginas u otras.
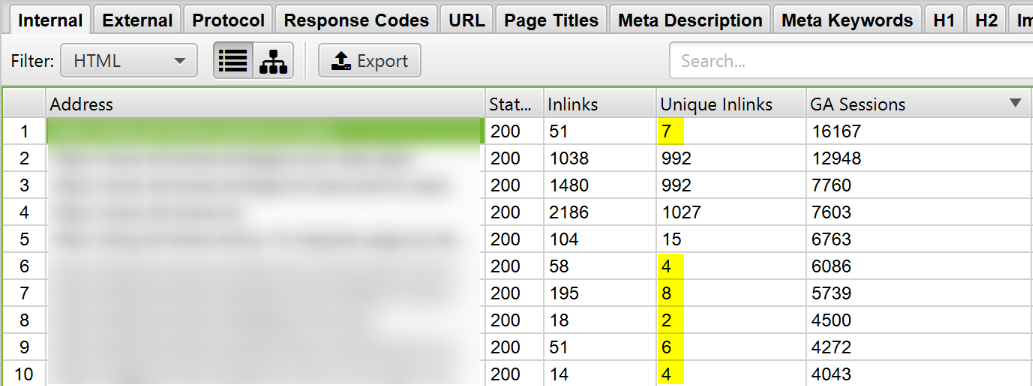
De nuevo, conectando la API de Analytics (o la de Search Console) podemos detectar oportunidades. En este ejemplo vemos como algunas páginas están captando mucho tráfico orgánico pese a que no se están enlazando mucho (en comparación con otras). Enlazándolas más y enriqueciendo su enlazado interno podríamos estar en disposición de captar más tráfico orgánico.
¿Cómo hacer un análisis del contenido que mejor funciona en tu blog?
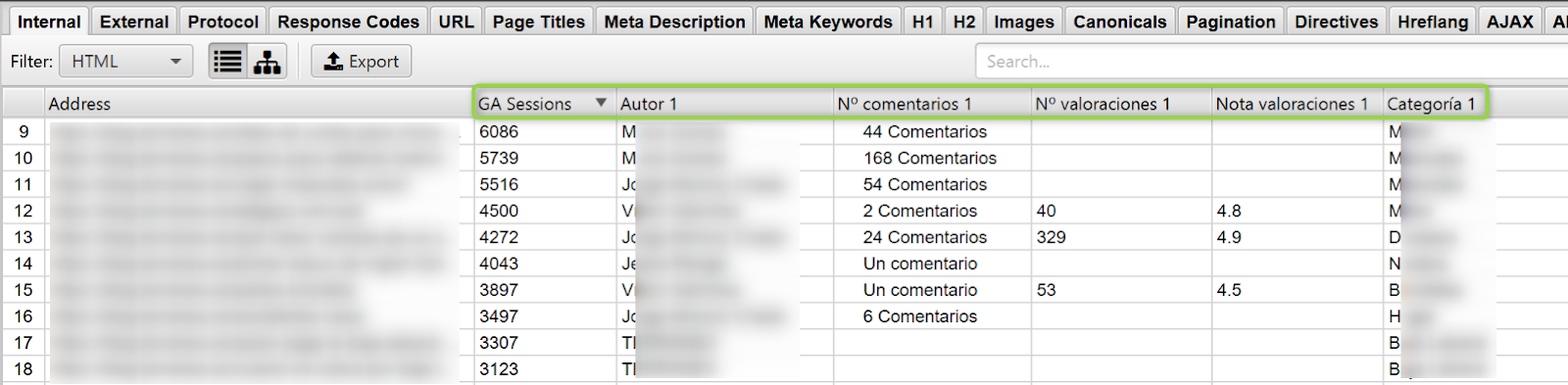
Más allá de las típicas métricas que nos ofrece Analytics sobre la calidad del contenido (tasa de rebote y tiempo en página), podemos scrapear otros datos visibles en la web que aporten gran valor.
En el siguiente ejemplo vemos algunos de los artículos que mejor están funcionando a nivel captación (sesiones orgánicas), la nota media de las valoraciones, cuántas valoraciones han dejado los usuarios, comentarios, quién ha sido el autor y a qué categoría pertenece el artículo.
Este tipo de análisis puede ser muy interesante para conocer mejor a la audiencia y saber qué contenidos funcionan mejor y cuáles peor.
¿Cómo identificar errores de renderizado?
Cada vez más se está extendiendo el uso de algunas librerías de Javascript (React, Vue, Angular…) que pueden causar graves problemas a los bots para poder rastrear una web correctamente. Para entender bien cómo ve un bot nuestra web antes de lanzarla es interesante configurar Screaming Frog para que renderice JS.
Lo primero que hacemos es seleccionar las siguientes opciones de almacenado de HTML.
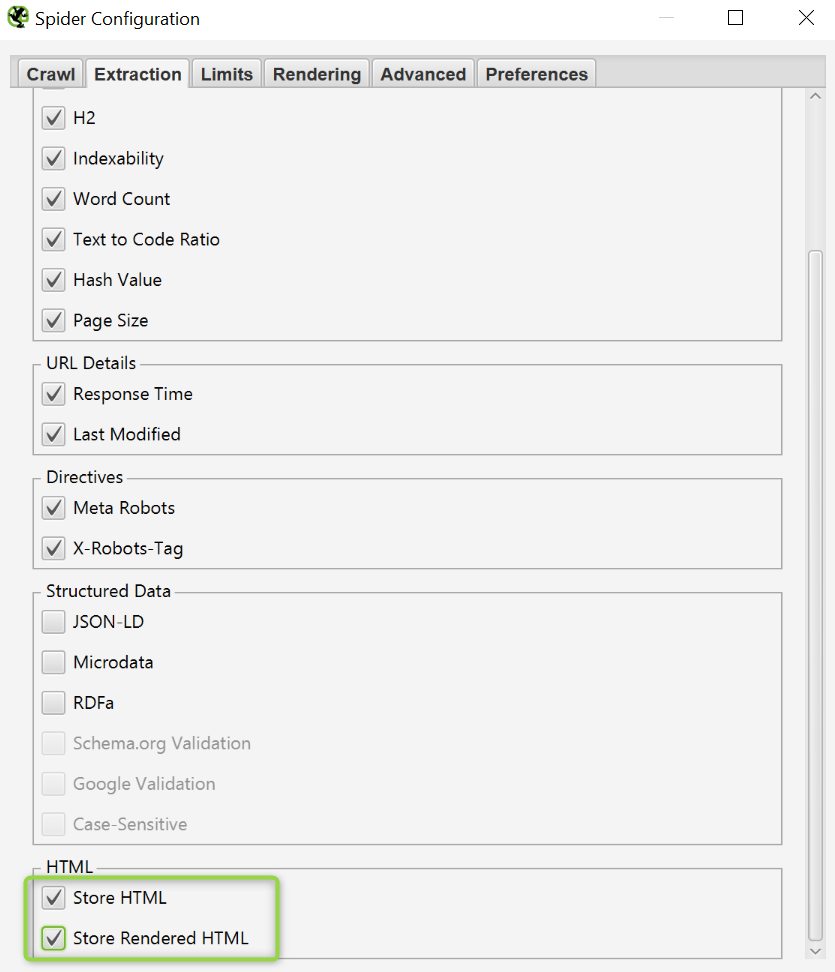
A continuación elegimos la opción Javascript y el bot con el que queremos analizar el site. Importante dejar seleccionada la opción de almacenar capturas de pantalla.
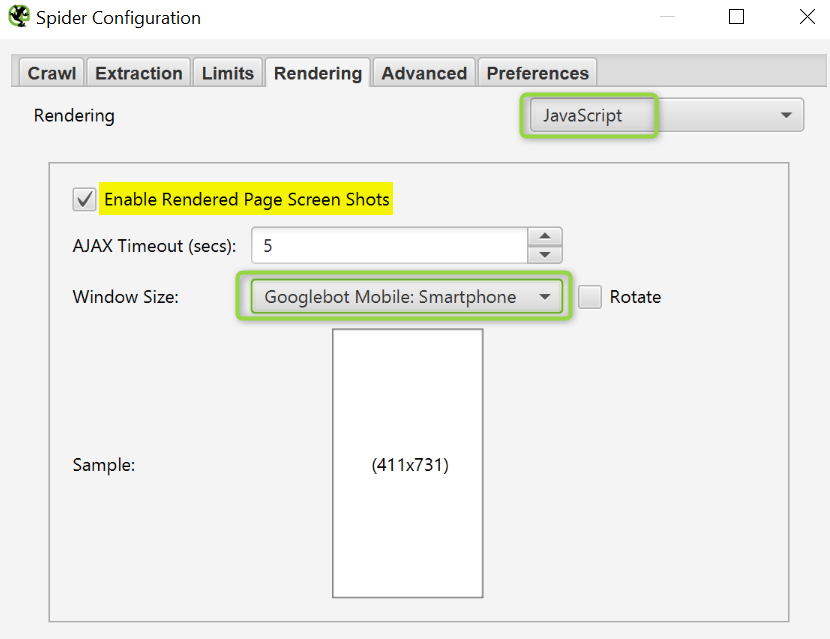
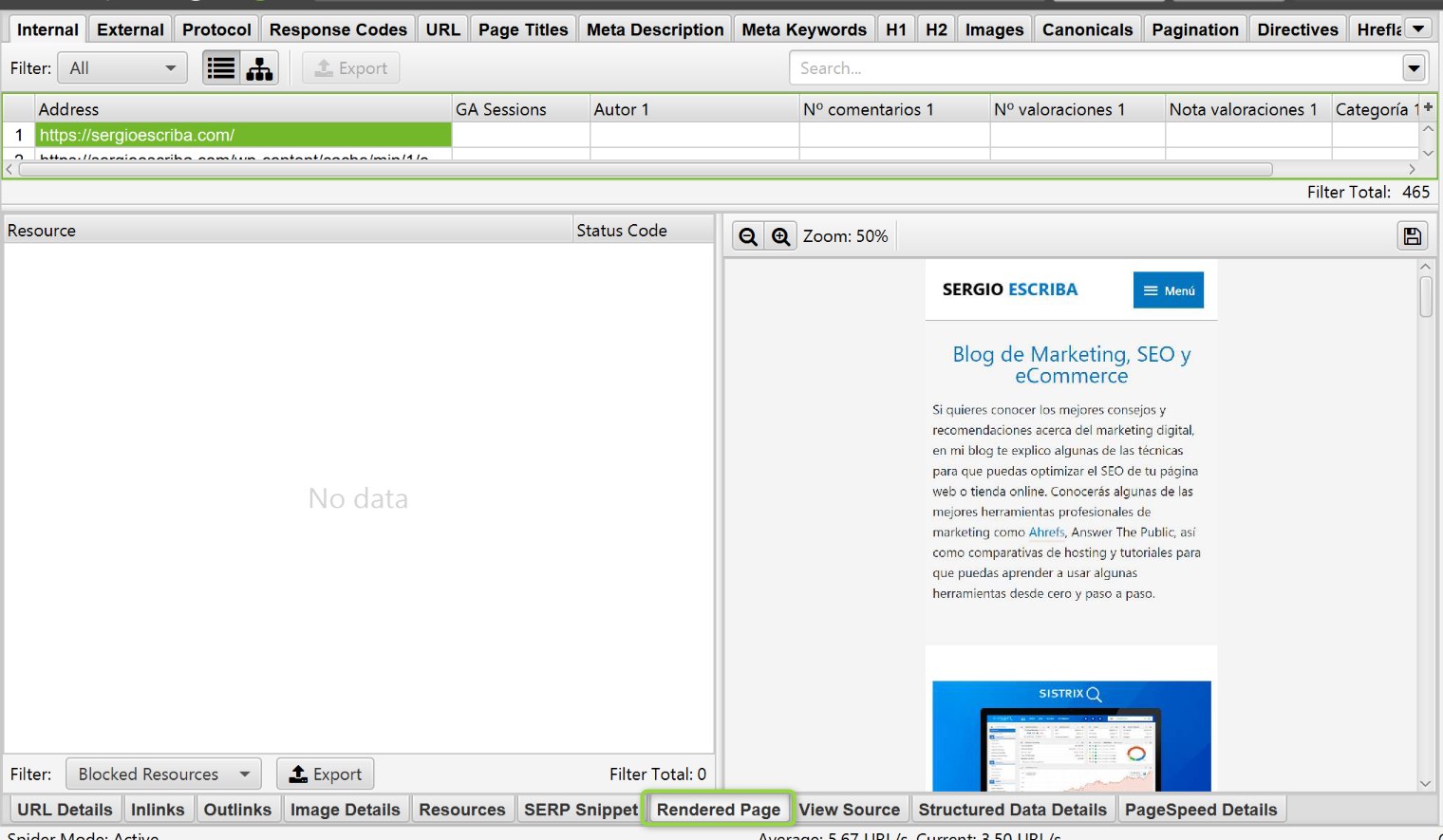
En la siguiente captura vemos cómo ve Googlebot la home de Sergio a nivel visual. Si aquí detectamos que hay elementos que no cargan, problemas.
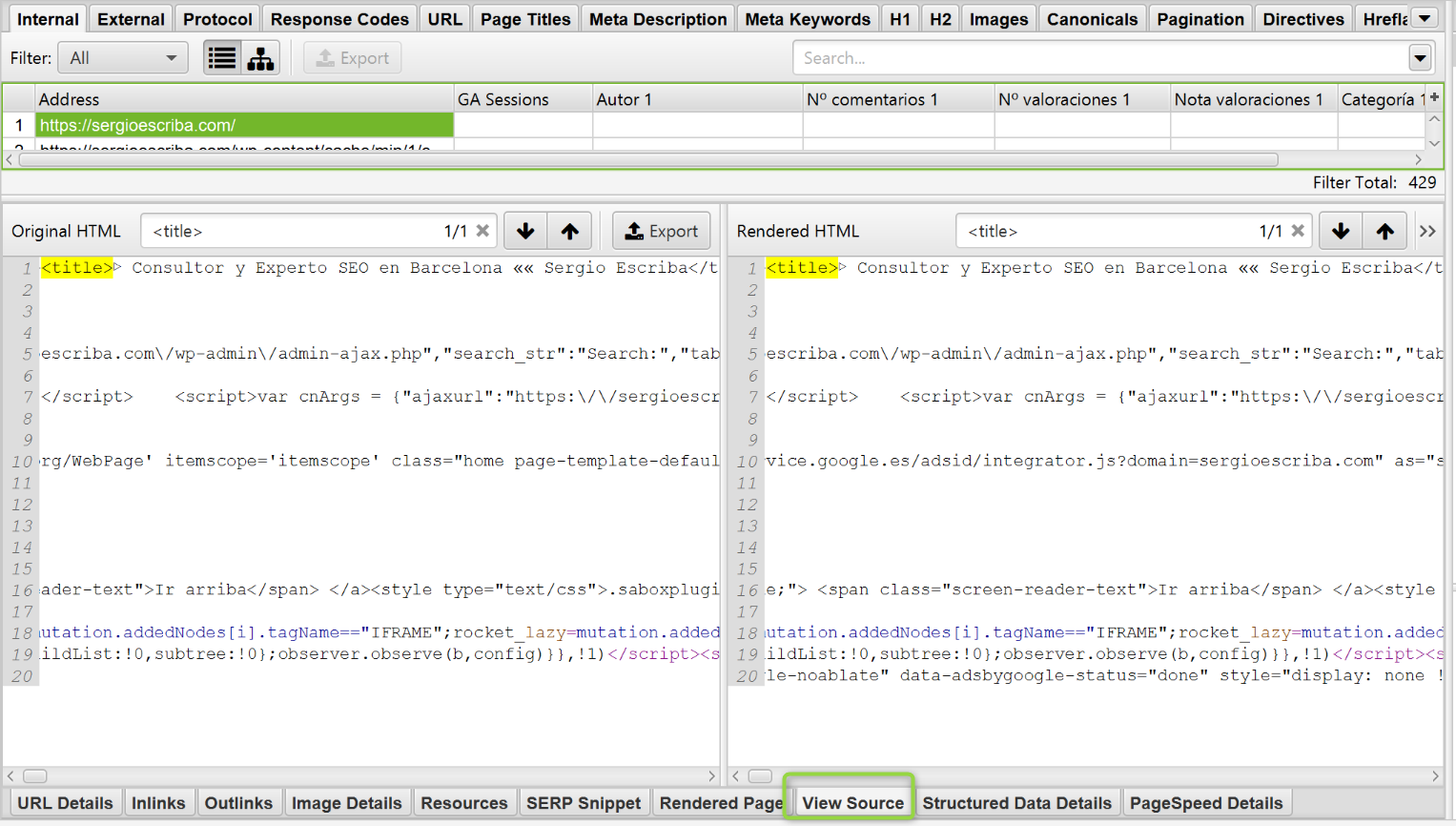
En este caso podemos comparar el código del HTML sin renderizar con el renderizado. Si encontramos grandes discrepancias en el contenido que carga, especialmente en etiquetas de HTML críticas a nivel SEO, problemas.
Hasta aquí este tutorial de Screaming Frog. Como puedes ver el límite lo marca tu imaginación, las opciones para sacarle provecho a la herramienta son infinitas.
¿Qué te ha parecido el artículo?
¿Tienes alguna duda?
Estaré encantado de leer tus apreciaciones.




¡Gracias por la guía Rodrigo! Sobre para todo los tips avanzados. La tenía en la lista de «pendientes de leer» y finalmente he podido tacharla 😉
Gracias Davide! me alegro que te haya resultado útil. Habrá que estar atentos a la próxima versión, han anunciado que está a punto de llegar, para seguir sacándole partido a la que es para mí la mejor herramienta SEO calidad precio sin lugar a dudas.
Saludos!
Genial guía!!! He probado la mayoría de cosas y hay dos cosas que se me resisten. A ver si pudiera ayudar, por favor.
– Por un lado, soy incapaz de crawlear un único directorio. Hago todo tal y como dices y acaba rastreando todo el dominio. ¿Pudiera ser porque sigue los links del menú y ya crawlea toda la web?
No sé si me explico…
– Por otro, lado, hay ocasiones es las que al conecdtar con la API de GSC me da error cuando pongo el filtro de país y excluyo las consultas de mi marca. ¿Alguna idea de por qué puede ser?
Muchas gracias y enhorabuena por el blog!! Está muy chulo!!
Hola Jaime,
¿Has mirado si te sigue pasando con las nuevas versiones que han sacado de la herramienta?
Contáctame por privado si sigues con problemas.
Saludos